The next Data Engineering change I am looking forward to

Note: originally published in 2022 in my medium blog and still very relevant in the ever-evolving data space.
In my last 3 companies, I started to get more involved in hiring Data Engineers. Every interview is different and unpredictable. But one thing is for sure, there is always a point where I or one of my colleagues will say:
“It’s hard to find Data Engineers.”
It might be the case that the interview process and questions we are asking are difficult. But seeing that this is becoming prominent, I feel that there is more to this problem.
We are all looking for a Unicorn
Before we dive deeper into understanding the problem of finding Data Engineers, can someone tell me what a Data Engineer really does?
Will it be:
- Someone who can do complex SQL queries
- Someone who creates data pipelines
- Someone who understands the meaning of ETL/ELT
- Someone who is familiar with Ralph Kimball
- Someone who works with Airflow, Spark, Hadoop, BigQuery, Hive, Python and other pokemons

All these are true but there are drastic differences in the job description from company to another, or even between teams.
One factor that might be contributing to this problem is how new the role of a Data Engineer is.
Data Engineers are the new kids on the block
From 2016 to 2020, Data Scientists have held the top spot in Glassdoor’s best jobs in America. This is unsurprising given that this role is also known to be the Sexiest Job of the 21st Century.
The increase in the number of data scientist opportunities paved the way for other data roles to get more attention. One of the roles that benefited from this is Data Engineer, which held the 3rd spot in 2017’s version of Glassdoor’s list. In the next few years, we will see an inconsistent trend from the same list.
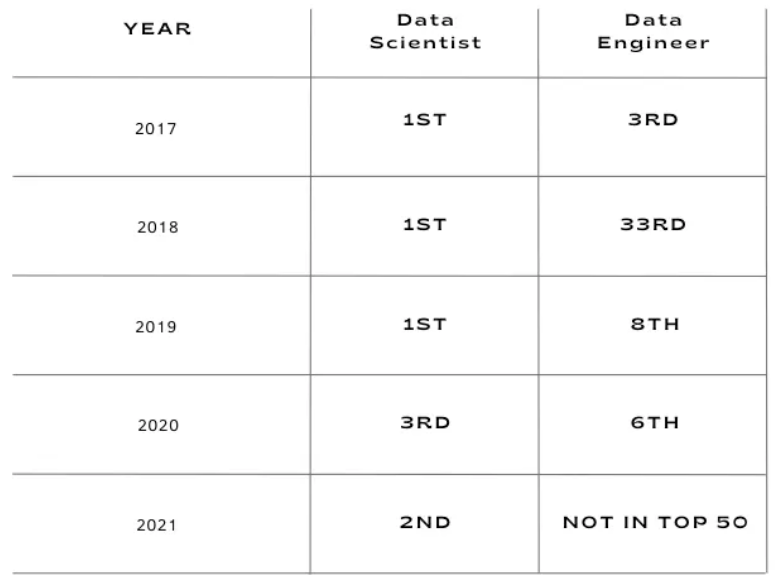
While this is a very particular market and specific list, it can still give us a glimpse of the current situation for Data Engineers.
Now in 2022, why is it still hard to find Data Engineers?
Maybe the supply has caught the demand and all positions are filled by most of the companies?
Maybe the role is not fun at all leading to a low job satisfaction?
Maybe data scientists ended up doing some of the responsibilities?
I have thought about this and realised that it might be a combination of all these things. But ultimately, we should stop looking for unicorns and try finding a horse and a rainbow instead. (The analogy is bad but I’ll stick with it)
Software Engineering = Data Engineering
The term unicorn isn’t new and has been used in Software Engineering and other tech roles. To solve our unicorn problem, one solution is to look into how Software Engineering roles are organized and compare it with Data Engineering.
There are different types of Software Engineers but for now let’s focus on 3 sub roles:
Frontend Engineers, Backend Engineers and Full Stack Engineers.
Now, the question is, will it be possible to also define Data Engineers in 3 sub roles?
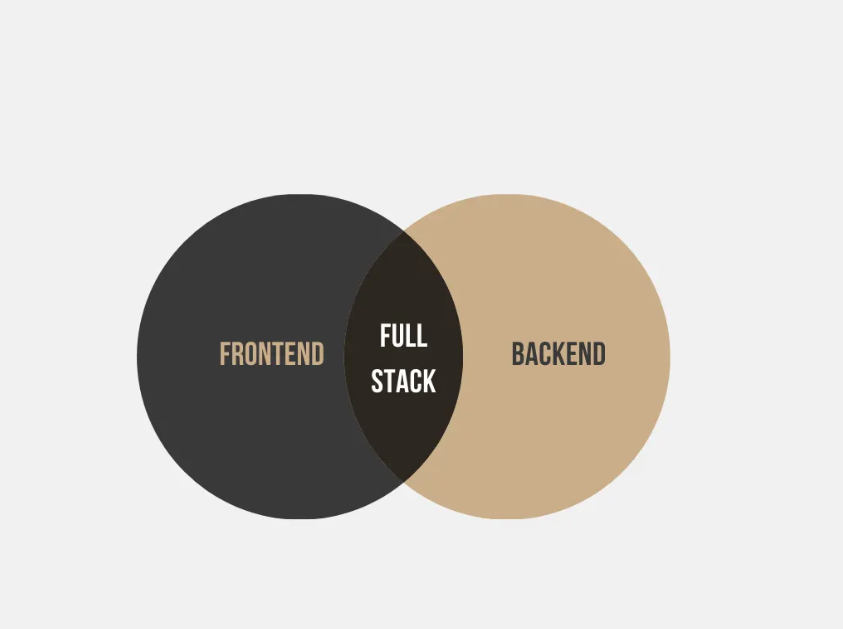
Frontend Engineer = Analytics Engineer
Frontend Engineers deal with the codebase that multiple users interact with like the login button, swiping left and right on an app or a change of font.
Similarly, Data Analytics Engineers are providing datasets to multiple users internally and externally. Other responsibilities that I see in this role are the following:
- providing the high quality and reliable datasets, usually in the form of databases and tables, that multiple users can use especially in dashboards and visualization tools
- transforming data into one form to another using ETL/ELT techniques
- working on complex SQL on a daily basis
Backend Engineer = Data Platform Engineer
Backend Engineers enable the Frontend Engineers to do their work by providing the infrastructure and data to be used by the web or mobile app.
Similarly, Data Platform Engineers should also support Data Analytics Engineers for the infrastructure needs. Other responsibilities that I see in this role are the following:
- enabling different systems to produce and consume data from a data lake
- ensuring that the data infrastructure can scale as number of users increase
- optimizing different combinations of data storage and query engines
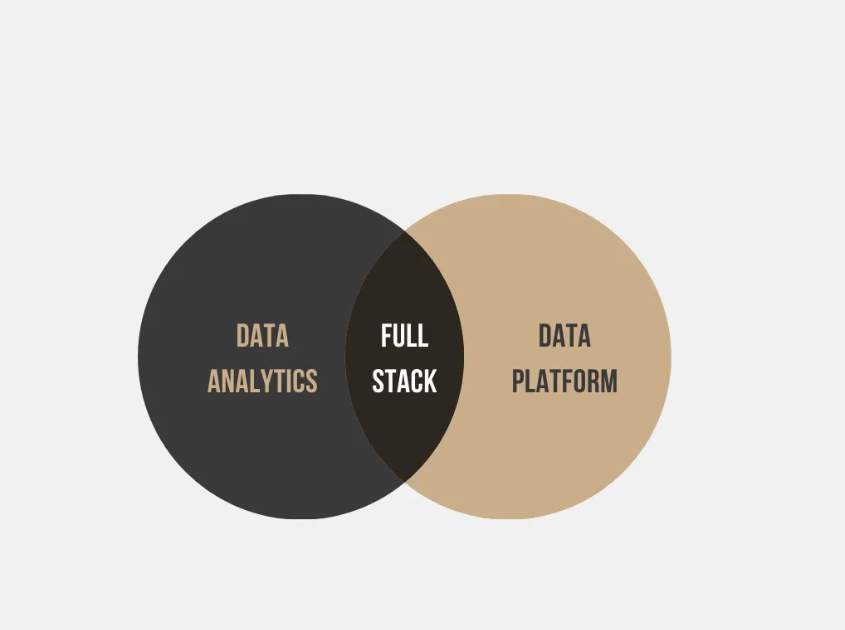
Full-stack Software Engineer = Full-Stack Data Engineer
Full-stack Engineers are the people who can deal with both sides of the coin.
Frontend and Backend Engineering are tightly coupled together and gaining knowledge on both roles only become an asset for you in the future.
Similarly, we need to start using the term Full-Stack Data Engineer if you also want to be involved in both Data Platform and Data Analytics. Other responsibilities that I see in this role are the following:
- ensuring end-to-end data flow from raw backend source until it’s ready for analytics consumption
- being the jack of all trades from creating data pipelines, setting the data infrastructure to data investigations
- working on real-time streaming to batch loading implementation of data pipelines
Looking forward to the future
As the data engineering world matures, we will see a lot of changes in terms of the tech stack. Hopefully, the roles and sub roles around data engineering follow maturity.
It might not be the same sub roles that I mentioned in this article but I think we will benefit a lot in being able to define these sub roles in the near future. It won’t be far enough that we will see roles such as DataOps, Data Quality Engineer, Data Reliability Engineer popping up.
Finally, job titles shouldn’t define the boundaries of what we can do.
But we should remember that these job titles also help others to transition and move to Data Engineering without drowning from the different areas that we need to learn.
This also helps current Data Engineers to identify gaps in their skillsets and enable them to either master a certain role or become that unicorn that everyone is looking for.
PS: I’d like to acknowledge the awesome data engineering unicorns who gave me feedback on this article. Thank you Mark, Mostafa, Jay-R, Haydar for all the insights you gave me!