A Week of Incident, Learning, and Relief

The Most Expensive Mistake (for now)
I probably made the most expensive engineering mistake of my life.
(Remind me in five years to revisit this post again if it’s still the most expensive one.)
It was one of those incidents that rarely happen, the kind that throws you into uncharted territory.
So here’s my attempt to share how it all transpired — and what I learned along the way.
When Accountability Hits Hard
While my team would say it was our responsibility, I still felt accountable. As an Engineering Manager, this was my oversight.
And in typical Jake-fashion—meaning I don’t just sit on the sidelines— so I rolled up my sleeves.
- Coding
- Debugging
- Monitoring
- Being in the “court” with the team
That’s how I switch to game mode. But even with all that energy, I quickly realized: some mistakes can’t be solved by sheer hustle.
The “Spilled Milk” Moment
That’s when it hit me. Sometimes no matter how hard you grind, the problem is simply bigger than you. And you need help.
It felt like spilling a full glass of milk the second you open the carton. That sinking feeling of guilt. But unlike spilled milk, engineering incidents can’t just be wiped away quietly and they shouldn't!
(Read this https://sre.google/sre-book/postmortem-culture/)
So instead of wiping the milk, I gave everyone context — both verbal and written.
- What happened
- What’s happening now
- What we want to do next
Because if we were going to fix this, everyone needed the same picture of reality.
As Winston Churchill put it, “Never let a good crisis go to waste.”
“On a Scale of 1–10, How F***ed Are We?”
At the end of the day, I took the elevator down and by chance bumped into another EM. We ended up walking together toward the train station — the kind of unplanned chat that only happens when you’re both too tired to pretend you’re fine.
The incident was still heavy on my mind, so I asked the only question that made sense in that moment:
“On a scale of 1–10, how fucked are we?”
My colleague didn’t give me a number. Instead, they said:
“Don’t worry about it. I should’ve recognized it sooner too.”
That answer didn’t magically fix the problem. But it did change something — it gave me reassurance that we weren’t alone.
The Surprise No One Expected
And just when I thought the week couldn’t surprise me further, it did.
A backend engineer from another team — less than six months into the company — quietly stepped in. Not loud, not flashy, just persistent.
- Asking for access
- Probing Slack channels
- Digging through metrics, logs, and even forgotten documentation
- Sharing findings, hypotheses, and assumptions—without the “brilliant asshole” energy
What struck me was how much impact someone outside my team could have. In just a few days, I learned more about this colleague’s grit and curiosity than in the entire six months they’d been here. Maybe that was the point — sometimes looking at a problem through a completely different lens is exactly what helps you see what the veterans can’t.
The ROI of Small Acts
Moments like this don’t come from nowhere. They come from culture.
And culture is built in the little things:
- Replying to a Slack thread
- Unblocking someone quickly
- Taking a question seriously
- Offering context even when it feels “small”
They don’t look like leadership at the time, but they’re the foundation of postmortem culture and resilient teams.
This week proved what I’ve always believed: psychological safety is one of the best investments in incident response.
The Question I Didn’t Expect
By Friday, I had my regular 1:1 with our most senior engineer. I joked:
“What a week, huh?”
We went through their growth, compensation, progression—the usual. At the end, I said, “You can add anything else if there’s more on your mind.”
My teammate paused, then asked something I didn’t see coming:
“How are you holding up?”
That stopped me cold. Because in the middle of firefighting, I hadn’t asked myself that once.
It was relief. Genuine, unexpected relief — the kind that comes not from solving the incident, but from realizing that yes, people notice.
Incidents happen and will happen, now what?
Incidents happen. Mistakes happen.
Even AWS S3 doesn't want to guarantee 100% availability even if I think it is.
Designed to provide 99.999999999% durability and 99.99% availability of objects over a given year.
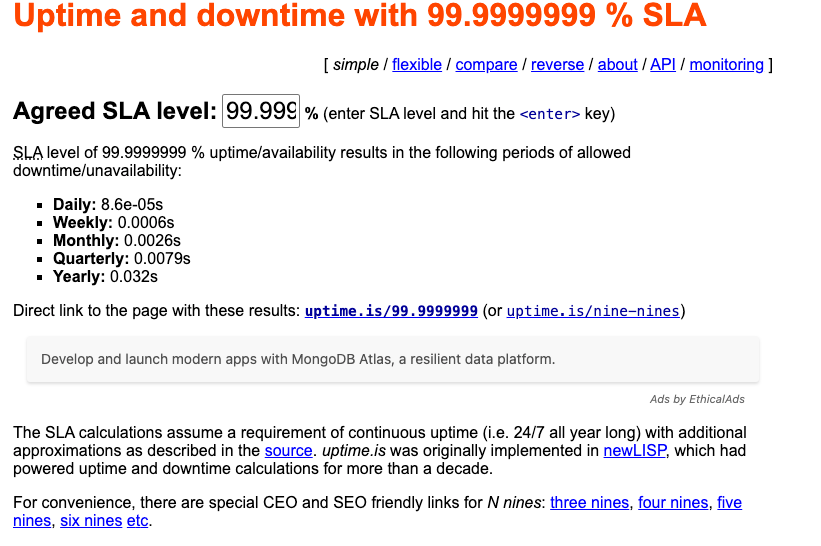
Aiming for perfect isn't the goal.
It should be preparing you and your team to handle incidents when they happen.